What’s next for eTMF
August 24, 2020
Electronic Trial Master file (eTMF) – one of the must-have software solutions for a pharmaceutical company or a CRO nowadays. Almost any company either already has one implemented or thinking about it (and if you are – check out our how-to article on moving from paper to eTMF!)
As everything, eTMF concept develops with time, moving from being just a place to store electronic versions of documents to a powerful tool, capable of making your business more efficient and bringing additional value.
Where do we start with eTMF?
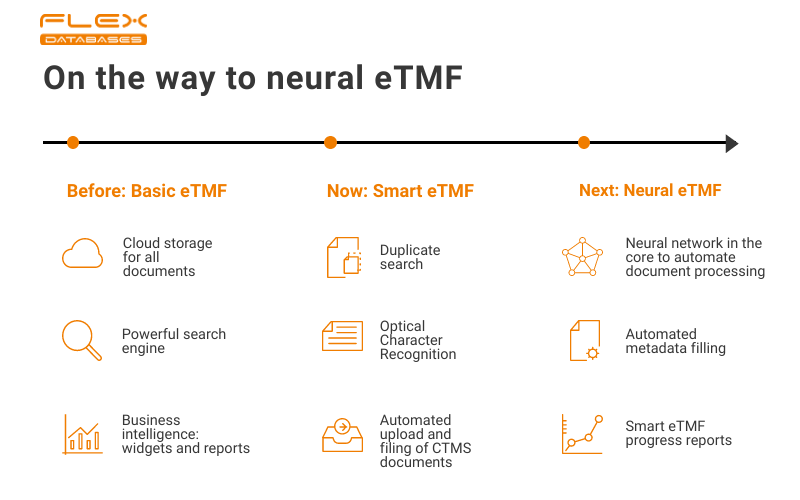
First of all, you should have the basics: secure storage, powerful search, audit trail, business intelligence tools, such as reports and widgets.The next step, where we are standing now, is Smart eTMF – when it gets to be more than just cloud storage. With this approach, you get a more autonomous system, where software starts taking care of specific tasks. You don’t waste time on continuous scanning and hand-placing anymore – you just drop a document via e-mail, and our system will place it into the pre-defined place, you can make any report based on any data, etc.If the Smart eTMF takes only a part of your activities, the next step of evolution, which we for now call a Neural eTMF, works with you and for you.As a beginning of the transformation from Smart to Neural eTMF, we’ve already implemented three things:
- Optical Character Recognition
- Duplicate search
- Autosource metadata
Optical Character Recognition (OCR)
Optical Character Recognition (OCR) tool recognizes text in non-text files (scans and pictures) and makes them searchable by its contents. Automatic text recognition on upload or single-file recognition via request is available in more than eight languages. OCR helps to make eTMF search as powerful as it could ever be by making all documents content-wise searchable – you can find everything you need in just a few clicks.
Duplicate search
The duplicate search feature is built based on a neural network and utilizes some of OCR functionality – whenever you make a file upload, our system analyzes the file’s content. It notifies the user in the case if there’s a duplicate already in the system. It helps not to overload your eTMF with duplicated files and keep the document structure clean.
Autosource metadata
The system reads a document through the OCR tool, recognizes any content that could be used as metadata, and completes the auto sourced metadata fill. Based on all this information, it files the document to the appropriate folder.
In conclusion
OCR allows the system to see the content, the neural network (as in duplicate search) analyze the content, and this together allows the system to place the document into the correct folder. In the end, you only have e-mailed the document but got it correctly set, described, and reported by the system.
Why do we need all of this, you may ask?
OCR, duplicate search and autosource metadata, along with their primary purposes, have one additional goal: saving users time. We work on our product to make future simple: soon you will be able just to e-mail any document to the system and let it go. eTMF will take care of the rest – placing, processing, reporting – by itself.
Present solutions may look cool enough for your today, but with our eTMF, we also take care of your tomorrow.
Sounds interesting?
If you want to know more – request a demo via the button on top of the page, or send us an e-mail to bd@flexdatabases.com.



